Clinical AI systems often include automated analysis of medical time series, such as electrocardiogram (ECG), to serve as valuable diagnostic decision support tools. While many cardiovascular diseases are traditionally measured by costly, less accessible imaging like echocardiograms, Anumana addresses this by employing an AI algorithm that analyzes a standard, widely available 12-lead ECG. Most existing literature focuses on classifying ECG into categories such as normal or abnormal. However, predicting continuous physiological measurements (like electrolyte levels or heart function metrics) from patient data is more valuable for clinical decision-making.
For instance, consider measuring electrolytes like potassium in blood. Excess potassium (hyperkalemia) can be fatal, and a binary classifier cannot distinguish between severity levels that determine different treatment plans. A major challenge is imbalanced data – extreme abnormal values are scarce compared to normal readings. In large ECG datasets, dangerously high serum potassium levels occur in only a tiny fraction of cases, whereas normal levels are abundant. A model trained naively on such skewed data will bias towards the common normal range, missing critical outliers. This is unacceptable in healthcare where life-threatening abnormalities might go undetected. Our team at Anumana developed a strategy using kernel density estimation (KDE) to rebalance training, enabling our deep models to pay proper attention to rare, clinically significant cases. This work is detailed in our paper, HypUC: A Framework for Handling Imbalanced Regression in Healthcare published in TMLR 08/2023.
The Challenge: Skewed Data in Clinical Regression
In clinical datasets, rare conditions create skewed label distributions. A clear illustration is shown below: most patients cluster in the normal range, while critical abnormal values form a long tail. The data are highly imbalanced: most potassium values lie around normal (≈4 mmol/L) with very few cases above 6 (hyperkalemia), and most LVEF values cluster near healthy levels (~60%) with far fewer in the dangerously low range.
Imbalanced distribution of Serum Potassium levels(left) and Ejection Fraction(right) in real-world clinical data.
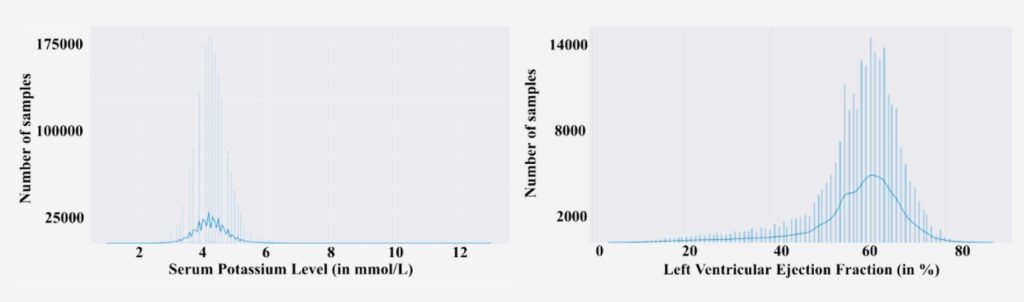
This imbalance poses a serious problem: standard training will be dominated by the vast number of normal examples, leaving the model poorly trained on the critical extremes. In effect, the model might minimize average error by doing well on normal cases while largely ignoring the outliers – the opposite of what clinicians need. longitudinal dataset.
All imbalanced learning methods, directly or indirectly, operate by compensating for the imbalance in the empirical label density distribution. This works well for class imbalance, but for continuous labels the empirical density does not accurately reflect the imbalance as seen by the neural network. Hence, compensating for data imbalance based on empirical label density is inaccurate for the continuous label space.We used a simpler, principled solution that leverages the density of the data to rebalance the training. Importantly, we had a secret weapon: the world’s largest, deepest clinical dataset. Anumana’s platform has aggregated electronic medical records (EMR) and other data modalities (ECG, EEG, labs, imaging, etc.) from millions of patients, creating an “AI-ready” longitudinal dataset.
KDE-based Rebalancing
Our solution introduces a kernel density estimation (KDE) weighted loss to focus learning on the rare cases.
Here’s how it works:
We first use KDE to estimate the probability density of the target variable across the training set. Intuitively, this gives us a smooth curve of how common each value is.
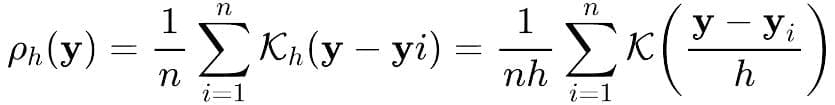
where 𝒦ₕ is a non-negative function often set to standard normal density function and h >0 is a smoothing parameter called bandwidth. The weighting scheme can be designed by leveraging the fact that lower-density samples must receive higher weights and vice-versa, a simple technique to achieve the same is to design the weight for target value y to be
w(y)=1/(ρh(y))λ. By tuning the exponent λ, we control how strongly to up-weight rare cases.
We found that a moderate weighting (not too extreme) gave the best results – effectively lifting up the tails of the distribution without overly distorting the rest.
KDE and related weights for imbalanced targets.
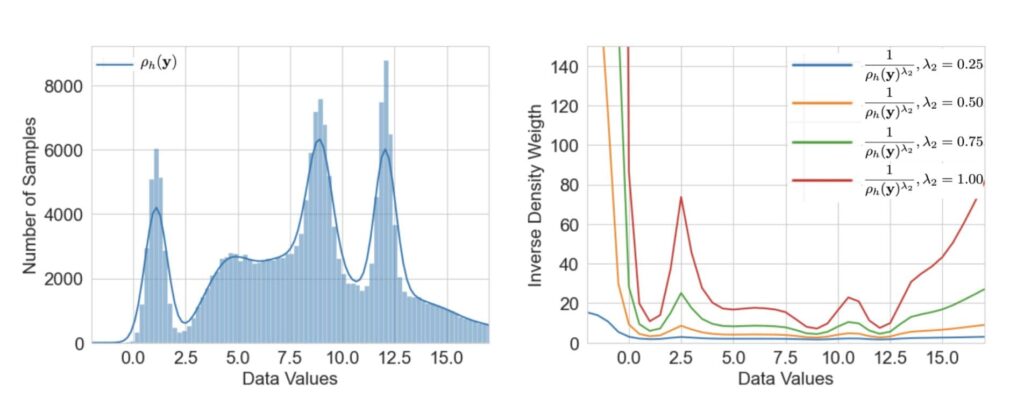
Critically, our enormous dataset makes the KDE approach feasible and robust. Estimating a density from sparse data could be noisy; but with millions of samples, our KDE is smooth and reliable even in the far tails. This approach is a prime example of how having massive, diverse, longitudinal data is a game-changer.
Results : Big Gains on Rare Cases
The impact of KDE-weighted training was striking. Our HypUC model (with KDE weighting + uncertainty estimation, discussed below) significantly outperformed conventional baselines on multiple clinical regression tasks. For instance, on an internal test for serum potassium prediction from ECG, adding the KDE-based imbalance correction reduced mean error on high-potassium cases by >20% compared to an unweighted model. We observed improvements in overall mean squared error (MSE) and correlation with ground truth for tasks like potassium and LVEF estimation when using the KDE-weighted loss.
Perhaps more importantly, the model no longer ignores the rare events. We can see it in the prediction results: cases of severe hyperkalemia that previously would confuse the model are now predicted much more accurately, thanks to the extra weight the model gave those training examples. An unexpected benefit is improved generalization: by not over-focusing on the dominant normal cases, the model learned more robust features that also helped moderate-abnormal cases. Essentially, handling imbalance made the model more calibrated across the board.
Imbalanced regression is just one piece of the puzzle in making clinically reliable AI. The HypUC framework goes further – it not only handles imbalance, but also provides uncertainty estimates and a mechanism to translate predictions into decisions. These will be covered in our subsequent posts.
For engineers and researchers reading this, if you’re excited by the idea of making AI not just accurate but honestly trustworthy, we invite you to explore opportunities with our team. We’re working on some of the hardest—and most rewarding—problems at the intersection of machine learning and medicine. By combining state-of-the-art algorithms, an unparalleled dataset, and a mission that matters, we’re pushing the frontier of what AI can do in healthcare. In our next post, we’ll discuss how we take these calibrated predictions and turn them into clinical decisions using an ensemble approach. Stay tuned!
References
1. HypUC: A Framework for Handling Imbalanced Regression in Healthcare
2. Delving into Deep Imbalanced Regression
Authors: Anumana Team