
Building on our previous discussion of imbalanced regression, we now turn to another critical challenge: uncertainty estimation. While addressing data imbalance helps models pay attention to rare cases, we must also ensure that when our AI makes predictions, it can honestly communicate how confident it is in those predictions. This work is detailed in our paper, HypUC: A Framework for Handling Imbalanced Regression in Healthcare published in TMLR 08/2023.
When an AI model analyzes a patient’s ECG and predicts a potassium level of 5.5 mmol/L, clinicians need to know: does the model’s 95% confidence interval span 5.2–5.8, or is it just making its best guess with no reliable bounds? This distinction is crucial in healthcare, where overconfident predictions could lead to wrong treatments, while underconfident ones might trigger unnecessary tests. The AI must “know what it doesn’t know” – a principle that forms the foundation of trustworthy clinical AI.
In our HypUC framework (Hyperfine Uncertainty Calibration), we developed techniques that go beyond simple point predictions. Instead of just outputting a single number, our models provide a full probability distribution that quantifies uncertainty. More importantly, we rigorously calibrate this uncertainty so it reflects reality. In this article, we’ll explore why uncertainty calibration is essential for clinical AI and how we achieved reliable uncertainty estimates that clinicians can trust with patients’ lives.
Why Uncertainty in AI Predictions is Crucial
Consider a model analyzing an ECG to predict a patient’s blood potassium level. If it predicts 5.5 mmol/L, is it certain this indicates hyperkalemia, or could the actual value be 4.5 mmol/L? The clinical response depends entirely on the model’s confidence interval. A careful clinician might order a confirmatory lab test if the model’s confidence interval is wide, whereas a tight interval around a critical value might prompt immediate intervention.
This scenario highlights a fundamental problem in traditional machine learning: many models, especially deep neural networks, are poorly calibrated. Their predicted confidence intervals don’t match actual error rates. A model might claim a “90% confidence interval” but only capture the true value 70% of the time — a dangerous overconfidence that could lead to clinical errors.
There are two types of uncertainty in deep learning: aleatoric (irreducible noise inherent in the data, such as measurement variability in ECGs) and epistemic (model uncertainty due to limited training data, which can be reduced with more samples). Our approach focuses on capturing aleatoric uncertainty by predicting a heteroscedastic Gaussian distribution for each input — meaning the model learns a different variance for each prediction, reflecting the inherent noise at that point in the input space. With millions of training samples, epistemic uncertainty is relatively low, making aleatoric uncertainty the dominant factor to model and calibrate.
In our work, we implement probabilistic regression: instead of predicting a single number, our models predict a full probability distribution (a Gaussian with mean and variance) for the target variable. Wider predicted distributions indicate greater uncertainty.
Probabilistic Regression Framework
In probabilistic regression, the model predicts the parameters of a probability distribution for each input, allowing it to express uncertainty in its predictions. A common choice is the Gaussian distribution, where the model predicts both the mean and the variance for a given input (ECG in our case).
The objective function is typically the negative log-likelihood of the observed data under the predicted distribution. For a Gaussian distribution, this is given by:
where:
- is the true target value for the -th sample
- is the predicted mean for the -th sample
- is the predicted variance for the -th sample
Explanation of the Components:
- Logarithmic Term:
- This term accounts for the uncertainty in the prediction. A larger variance implies more uncertainty, which increases the log-likelihood penalty.
- Squared Error Term:
- This term measures how far the predicted mean is from the actual target value, scaled by the predicted variance. If the model is confident (small $\sigma^2(\mathbf{x}_i)$), deviations from the mean are penalized more heavily.
The goal of the objective function is to find the parameters of the model that minimize the negative log-likelihood across all training samples. This ensures that the model not only predicts accurate means but also provides reliable estimates of uncertainty. By optimizing this function, the model learns to balance the trade-off between fitting the data well and expressing appropriate uncertainty.
Beyond statistical metrics, the practical impact of calibrated uncertainty is profound: it enables safer integration of AI into clinical workflows. Our model can flag predictions as “uncertain” when the predicted confidence interval is too wide or has high entropy, alerting clinicians to step in or suggesting follow-up diagnostic tests. Conversely, when the model produces a tight confidence interval, it can enable faster clinical decisions.
Our Approach: Global + Hyperfine Uncertainty Calibration
Regulators and clinicians are far more comfortable with AI that can honestly express uncertainty. It’s analogous to a junior doctor saying “I’m not entirely sure, let’s double-check”—a humble approach that’s infinitely better than unfounded certainty.
However, we discovered that this raw uncertainty often requires calibration to align with reality, particularly in the distribution tails or underrepresented regions. Uncertainty calibration involves adjusting the model’s predictive distribution so that its uncertainty statements are statistically valid. If the model claims “the true value lies within this 95% confidence interval,” then in practice, the true value should fall within that interval about 95% of the time.
Uncertainty Calibration Error (UCE)
We quantify calibration quality using the Uncertainty Calibration Error (UCE). For a given confidence level , we define the prediction interval as:
where is the quantile function (inverse CDF) of the predicted distribution. For a Gaussian at , . UCE then measures the gap between the expected and actual coverage:
A UCE of 0 means perfect calibration: exactly fraction of true values fall within the predicted interval. Our goal is to minimize UCE while also keeping the interval length small — a well-calibrated model that simply predicts enormous intervals would have low UCE but be clinically useless.
Predicting uncertainty is one thing; calibrating it is another challenge. We took a two-stage approach in HypUC: global calibration followed by “hyperfine” calibration.
Global uncertainty calibration: After training our probabilistic regression model, we find a single scaling factor to adjust all predicted variances. We solve on a held-out validation set $\mathcal{D}{\text{valid}} = {(x_i, y_i)}{i=1}^{M}$:
This is analogous to temperature scaling in classification. In classification, temperature scaling adjusts a single scalar applied to logits to calibrate predicted class probabilities (i.e., making a model that claims 90% probability actually be correct 90% of the time). Similarly, our global calibration finds a single factor applied to all predicted variances , ensuring the overall coverage of prediction intervals matches the target confidence level. It corrects any overall tendency of the model to be over- or under-confident. However, one scaling factor cannot capture all the nuanced variations across different prediction ranges.
Hyperfine calibration: We partition predictions into hyperfine bins based on their predicted value range and compute a specialized scaling factor for each bin. For each bin, we solve:
where is the target coverage fraction. This addresses the issue that models might be well-calibrated on average but still miscalibrated for specific ranges — too uncertain for moderate values, not uncertain enough for extremes. The final calibrated uncertainty for a prediction is:
The result is a calibrated prediction like “ECG analysis predicts potassium = 5.5 ± 0.3” where the ±0.3 truly represents a reliable standard deviation range. The entire process is post-hoc, meaning we adjust outputs without retraining the neural network. We use a held-out validation set to learn the calibration parameters, building on prior methods like Laves et al. (2020) but extending to multi-factor hyperfine calibration for superior performance on large, imbalanced datasets.
Evidence: Reliable Uncertainty, Verified
How do we know our approach worked? We evaluated HypUC’s uncertainty calibration on multiple clinical tasks (age prediction, survival time prediction, serum potassium, LVEF) using our test sets, measuring UCE and the percentage of true values falling within the model’s predicted confidence intervals. The calibrated model achieved very low UCE, indicating excellent alignment between predicted and actual uncertainties. For instance, the standard probabilistic baseline (Regres.-w.-U) had a UCE of 13.32 on age estimation, while HypUC brought it down to 1.06. On serum potassium, UCE dropped from 1.83 to 0.41.
For example, prior to calibration, a task’s 95% confidence interval might only cover 88% of true values (UCE of 7%). After our two-stage calibration, it covered approximately 95% as intended, with appropriately tight interval widths.
The figure below compares the model’s predicted distribution against the ground truth distribution across many examples. Each subplot shows the relationship between predicted values and true values. The red line/area represents the peak and spread of the ground truth distribution, while the blue line/area represents the peak and spread of the model’s calibrated predicted distribution (HypUC). Ideally, the blue (prediction) region should overlap the red (actual) region.
Ground truth vs. HypUC predicted distributions for Age, Survival, Serum Potassium, and LVEF estimation. Blue (predicted) regions tightly encompass red (ground truth), indicating well-calibrated uncertainty.
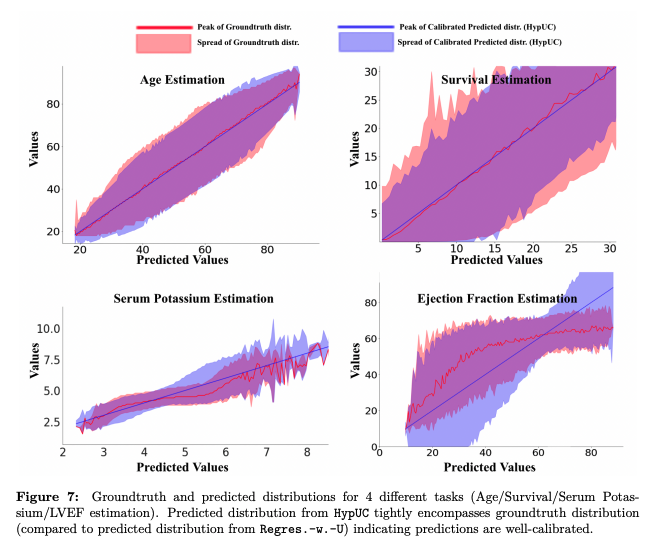
For all four tasks, the HypUC predictive distributions tightly encompass the true values (blue covers red), indicating that the model’s uncertainty estimates are well-calibrated. In other words, when HypUC produces a 95% confidence interval, the true value falls within that interval about 95% of the time — across all these varied clinical tasks. This level of calibration is a significant improvement over standard probabilistic models, which have historically struggled with reliable uncertainty measures.
We also tested how calibrated uncertainties can be used in clinical workflows. We compute the entropy of each prediction’s calibrated distribution, , and flag predictions above an entropy threshold as unreliable. By removing the 10% of test samples with the highest entropy, the model’s MAE on the remaining 90% drops consistently across all tasks. This demonstrates that our uncertainty metric effectively identifies the trickiest cases where the model was likely to err. In clinical practice, this means the AI can handle routine cases automatically while flagging challenging ones for human review — a safe and intelligent deployment paradigm.
Hyperfine calibration requires enough data in each bin to learn reliable bin-wise scaling factors. With millions of samples spanning different hospitals, patient populations, and modalities, our calibration is smooth and trustworthy even in the far tails of the distribution where clinical stakes are highest.
Building Trustworthy AI, One Uncertainty at a Time
Calibrating uncertainty is not merely a technical exercise — it’s about building trustworthy AI for healthcare. By ensuring our models can honestly express their limitations through reliable confidence intervals, we make them significantly more valuable and clinically safe. Our work on HypUC demonstrated that it’s possible to achieve highly reliable uncertainty estimates even in complex deep learning models operating on noisy biosignals. This sets the stage for a new paradigm of AI assistance: one that can be transparent about what it knows and what it doesn’t. We believe this transparency is fundamental to the future of AI in medicine — it’s how we transform opaque algorithms into tools that clinicians can confidently rely on.
The HypUC framework goes one step further: it uses both the calibrated uncertainty and the predicted continuous value as features for an ensemble of gradient-boosted decision trees, translating probabilistic predictions into clinical decision categories (e.g., normal vs. hyperkalemia severity levels). This bridges the gap between raw model output and actionable clinical decisions — a topic we’ll explore in a future post.
For engineers and researchers reading this, if you’re excited by the idea of making AI not just accurate but honestly trustworthy, we invite you to explore opportunities with our team. We’re working on some of the hardest — and most rewarding — problems at the intersection of machine learning and medicine. By combining state-of-the-art algorithms, an unparalleled dataset, and a mission that matters, we’re pushing the frontier of what AI can do in healthcare.
{kind=link}